Pipelines
Feldera expresses incremental computations via Pipelines. A Pipeline is defined using SQL tables and views. Pipelines receive input data
through input connectors. Pipelines can send the results computed by views to destinations via output connectors.
Pipeline architecture
The diagram below illustrates the internal architecture of a Feldera pipeline:
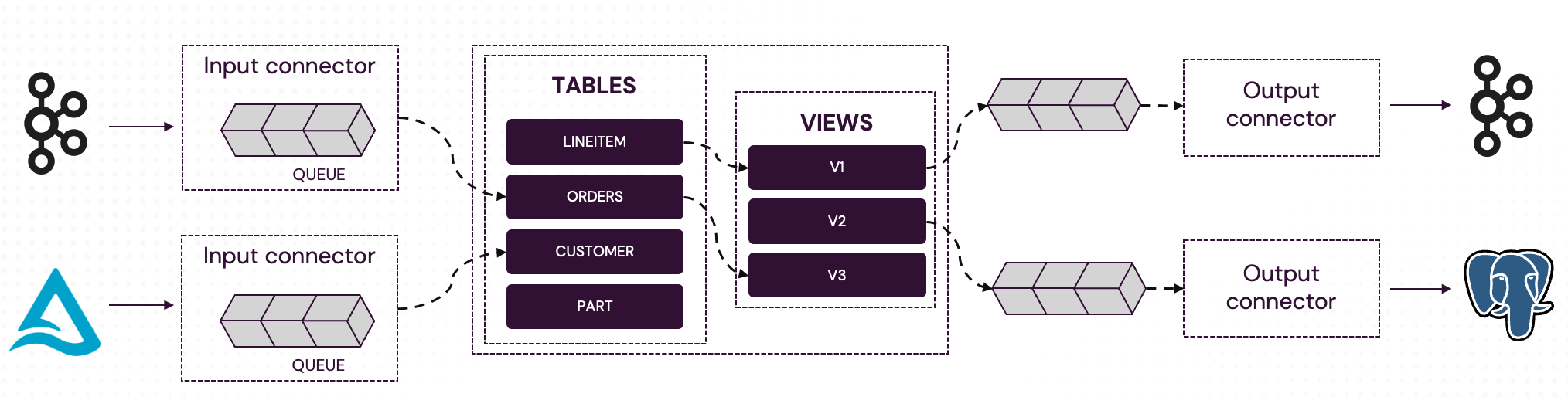
-
Input connectors ingest data from external sources such as message queues, databases, and data lakehouses. A pipeline can have multiple input connectors of different types, including several connectors feeding the same table. An input connector buffers data in its internal queue until the SQL engine is ready to accept more inputs.
-
Incremental SQL engine. The Feldera SQL engine ingests buffered input data as changes to internal SQL tables. It performs Incremental View Maintenance (IVM), efficiently computing updates to SQL views based on input changes.
-
Output connectors send changes to external data sinks. Like input connectors, a pipeline can have any number of output connectors of different types and there can be multiple output connectors attached to the same table. Output data is buffered in an internal queue until the connector is ready to send it downstream.
Connectors
A connector is a combination of two things: a transport and often a format. The transport describes where the input data comes from or output data is sent to (e.g., Kafka, S3, PubSub and so on). The format defines the shape or envelope of the data (e.g., JSON, CSV, Parquet and more). Typically, the format has to be compatible with the schema of the tables and views.
Read the references below to learn more about SQL pipeline features.
🗃️ Feldera SQL
10 items
🗃️ Connectors
6 items
🗃️ Formats
5 items
📄️ Reference: Pipeline Lifecycle
A pipeline's lifecycle goes through several states as the control plane allocates compute and storage resources for it.
📄️ Settings
Pipelines come with a set of configuration settings to toggle features, tune performance, and help with operations. If you're on the Enterprise Edition, you will likely need to configure the resources section to tune the CPU, memory, and storage resources used by the Pipeline depending on your infrastructure needs. Other than that, users rarely need to deviate from the supplied defaults.
📄️ Fault tolerance and checkpoint/resume
Checkpoint/resume and fault tolerance are only available in Feldera Enterprise Edition.
📄️ Modifying a Pipeline
This feature is only available in Feldera Enterprise Edition.
📄️ Synchronizing checkpoints to object store
Synchronizing checkpoints to object store is a highly experimental feature.
📄️ Efficient Bulk Data Processing using Transactions
Transaction support is an experimental feature and may undergo significant
📄️ Measuring Pipeline Latency
Incremental View Maintenance (IVM) enables Feldera to quickly incorporate changes to input data into analytical queries.
📄️ Sidecar Containers
This feature is only available in Feldera Enterprise Edition.