Introduction
Documentation sources
Parts of this documentation are adapted from the Postgres Database documentation, governed by the Postgres license.
Parts of this documentation are adapted from the Calcite documentation, governed by the Apache 2.0 License.
Feldera, DBSP and incremental view maintenance
Feldera's implementation is based on a query engine optimized for incremental view maintenance. This engine is called Database Stream Processor, DBSP.
Feldera is used in the following way:
- users define a set of database tables in Feldera. These tables become inputs for DBSP.
- users define a set of database views. The views become outputs for DBSP
(unless they are declared as being
LOCAL). The views are implemented in standard SQL, and compiled to Rust using the SQL to DBSP compiler. - the compiled DBSP program is started
- DBSP assumes that the tables are initially empty
- users inform DBSP of any changes of the input tables
- in response DBSP computes the changes to the output views caused by these changes and emits them as outputs
A DBSP program behaves as a streaming system. A stream is simply a sequence of changes. Thus DBSP implements standing queries: the queries are installed prior to the data arrival, and then are continuously executed for each input change. A DBSP standing query transforms a stream of input table changes into a stream of output view changes.
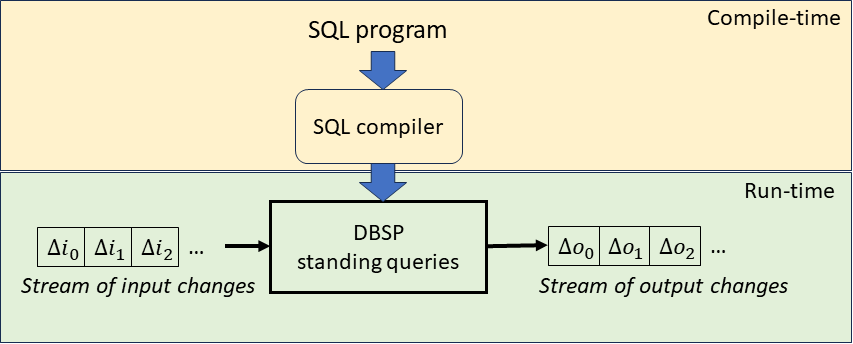
Notice that an input change can affect multiple tables. Moreover, input changes can contain both insertions and deletions from the input tables. Similarly, for each input change there is a corresponding output change that affects all output views. Changes in the output views are specified in terms of insertions and deletions.
Limitations
DBSP is not a database, it is just a query engine. DBSP is not designed to replace a standard database, but to work in conjunction with an existing one.
Differences between DBSP and a database:
-
DBSP queries are standing queries, and are designed to be executed continuously.
-
A traditional database offers durable storage of data. In general, DBSP does store the contents of the data, either for the tables or the defined views. DBSP will only store sufficient data to compute the changes. DBSP can be configured to store the data for tables and views.
-
DBSP does not currently provide any concurrency control mechanisms, or transactions. DBSP is simply a stream processing engine, where each input change produces a corresponding output change.
-
Other traditional database constructs, such as triggers, or multi-version concurrency control, do not make sense for a system like DBSP.
Supported SQL Constructs
Feldera offers a powerful set of features:
-
A rich set of data types, including the standard SQL datatypes, dates, times, intervals, arrays, maps, user-defined types, variant
-
Arbitrary SQL queries, including the standard relational algebra,
GROUP BY, aggregations, user-defined functions, joins of several flavors,UNNEST, and window queries -
Feldera uses a different syntax (and semantics!) than standard SQL for recursive queries.
-
Feldera provides some small extensions to SQL which make writing programs for streaming data more convenient
There are many good introductions to SQL on the Internet. This document is not intended as a tutorial, but only as a specification of the features of SQL implemented on top of DBSP.
SQL as a language has been standardized for a long time. Unfortunately, the standard leaves underspecified many important behaviors. Thus each SQL implementation is slightly different.
The SQL to DBSP compiler is implemented on top of the Apache Calcite infrastructure. While Calcite is a very flexible and customizable platform, it makes several choices regarding the SQL language semantics. Our implementation mostly follows these choices. This document describes specifics of our implementation.