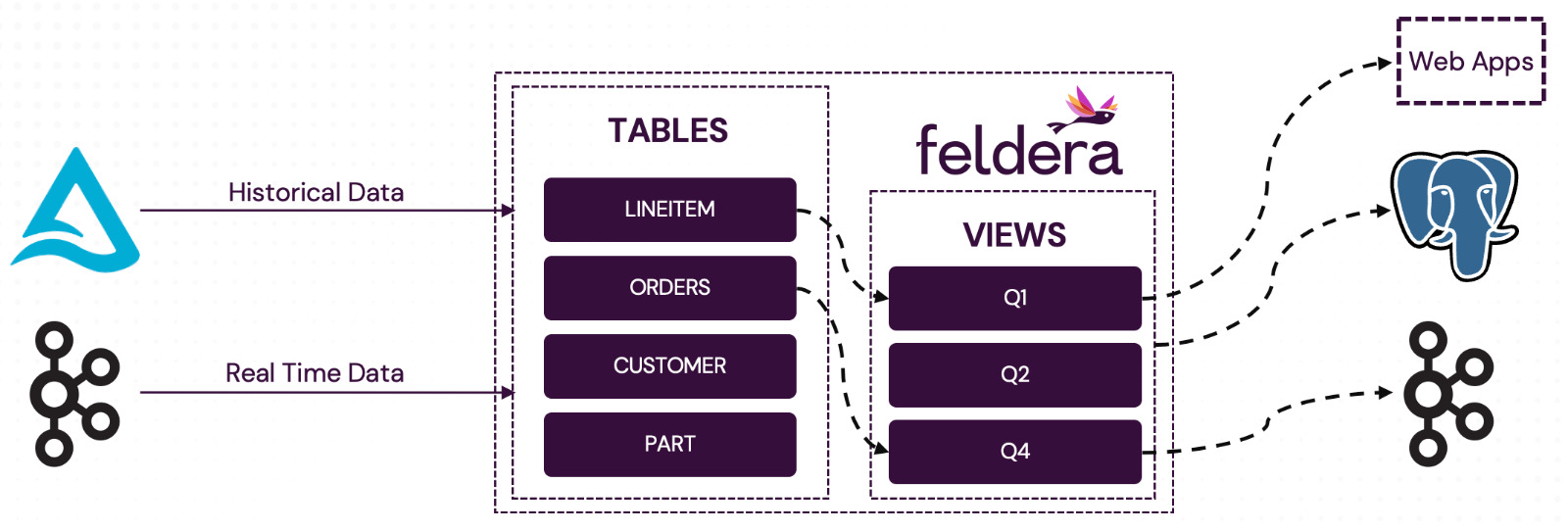
Part 4. Sending Output to Multiple Destinations
Once data has been processed, the next step is to deliver it to downstream systems. Feldera supports this through output connectors, which can continuously push the contents of the views to a variety of destinations.
Common use cases include:
- Writing aggregated and enriched data to PostgreSQL
- Publishing real-time changes to a Kafka topic
- Sending updates to web applications via HTTP
PostgreSQL: Real-Time Materialized Views
Feldera can be used to incrementally maintain materialized views in
PostgreSQL. Unlike traditional materialized views, which must be manually
refreshed (by running the query REFRESH MATERIALIZED VIEW q1), these views
stay in sync with Feldera as changes happen.
Step 1: Create the Target Table in PostgreSQL
We connect to PostgreSQL instance running locally:
psql postgres://postgres:password@localhost:5432/postgres
Create a table q1 that will receive output from the Feldera view:
-- PostgreSQL
CREATE TABLE q1 (
l_returnflag CHAR(1) NOT NULL,
l_linestatus CHAR(1) NOT NULL,
sum_qty DECIMAL(15,2),
sum_base_price DECIMAL(15,2),
sum_disc_price DECIMAL(15,2),
sum_charge DECIMAL(15,2),
avg_qty DECIMAL(15,2),
avg_price DECIMAL(15,2),
avg_disc DECIMAL(15,2),
count_order BIGINT,
PRIMARY KEY(l_returnflag, l_linestatus)
);
Step 2: Define an Index for Output View
Create an index on the unique key columns so that updates and deletions in PostgreSQL can be tracked correctly:
create index q1_idx on q1(l_returnflag, l_linestatus);
This index needs to be defined after the view definition.
Step 3: Configure Output Connector in Feldera
Next, we define the output connector for the view to send updates to PostgreSQL. See docs: PostgreSQL output connector.
-- Feldera SQL
create materialized view q1 with (
'connectors' = '[{
"index": "q1_idx",
"transport": {
"name": "postgres_output",
"config": {
"uri": "postgres://postgres:password@localhost:5432/postgres",
"table": "q1"
}
}
}]'
) as select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
lineitem
where
l_shipdate <= date '1998-12-01' - interval '90' day
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
Note the index attribute that links this PostreSQL connector to the q1_idx
index declared above. This enables the connector to group changes to the same
unique key in the output stream as described
here.
Step 4: Verifying the Output in PostgreSQL
Once the pipeline is running, Feldera will continuously update the view q1 and
push its output to the target table defined in PostgreSQL. We can verify that
data is flowing correctly by querying the target table:
SELECT * FROM Q1;
Result:
| l_returnflag | l_linestatus | sum_qty | sum_base_price | sum_disc_price | sum_charge | avg_qty | avg_price | avg_disc | count_order |
|---|---|---|---|---|---|---|---|---|---|
| A | F | 3,774,200.00 | 5,320,753,880.69 | 5,054,096,266.68 | 5,256,751,331.45 | 25.53 | 36,002.12 | 0.05 | 147,790 |
| N | F | 95,257.00 | 133,737,795.84 | 127,132,372.65 | 132,286,291.23 | 25.30 | 35,521.32 | 0.04 | 3,765 |
| N | O | 7,459,297.00 | 10,512,270,008.90 | 9,986,238,338.38 | 10,385,578,376.59 | 25.54 | 36,000.92 | 0.05 | 292,000 |
| R | F | 3,785,523.00 | 5,337,950,526.47 | 5,071,818,532.94 | 5,274,405,503.05 | 25.52 | 35,994.02 | 0.04 | 148,301 |
Kafka
A pipeline can have multiple output connectors sending data to a variety of destinations.
These connectors can be attached to the same or different SQL views.
For example, we can publish the output of q2 to a Kafka topic:
-- Feldera SQL
create materialized view q2 with (
'connectors' = '[{
"transport": {
"name": "kafka_output",
"config": {
"bootstrap.servers": "localhost:9092",
"topic": "q2_output"
}
},
"format": {
"name": "json",
"config": {
"update_format": "insert_delete",
"array": false
}
}
}]'
) as
select ...
Web Apps / HTTP
Web applications and backend services can receive live updates from Feldera using the HTTP output connector. This enables applications to consume real-time data streams over standard HTTP. Feldera can stream updates as they happen without constant re-polling.
Streaming with curl
Live stream of updates to the view can be observed using the following curl
command:
curl -i -X 'POST' http://127.0.0.1:8080/v0/pipelines/batch/egress/q2?format=json
As the contents of the view change, the changes will be streamed continuously.
Streaming in Python
Feldera's Python SDK provides a high-level API to subscribe to view updates in Python applications.
The following snippet demonstrates how to register a callback that runs for every chunk of update:
from feldera import Pipeline, FelderaClient
# define your callback to run on every chunk of data received
# ensure that it takes two parameters, the chunk (DataFrame) and the sequence number
def callback(df: pd.DataFrame, seq_no: int):
print(f"\nSeq No: {seq_no}, DF size: {df.shape[0]}\n")
pipeline = Pipeline.get("batch", FelderaClient.localhost())
# register the callback for data received from the selected view
pipeline.foreach_chunk("q3", callback)
# run the pipeline
pipeline.start()
# wait for the pipeline to finish and shutdown
pipeline.wait_for_completion(shutdown=True)
This is useful for:
- Updating live dashboards
- Triggering side effects in response to new data
Takeaways
- Feldera allows streaming data directly to popular data sinks like PostgreSQL, Kafka, Delta Lake and Redis.
- By connecting Feldera's incremental SQL engine to different sources and destinations, you can query data from multiple independent sources and materialize the results in multiple independent destinations in real-time.