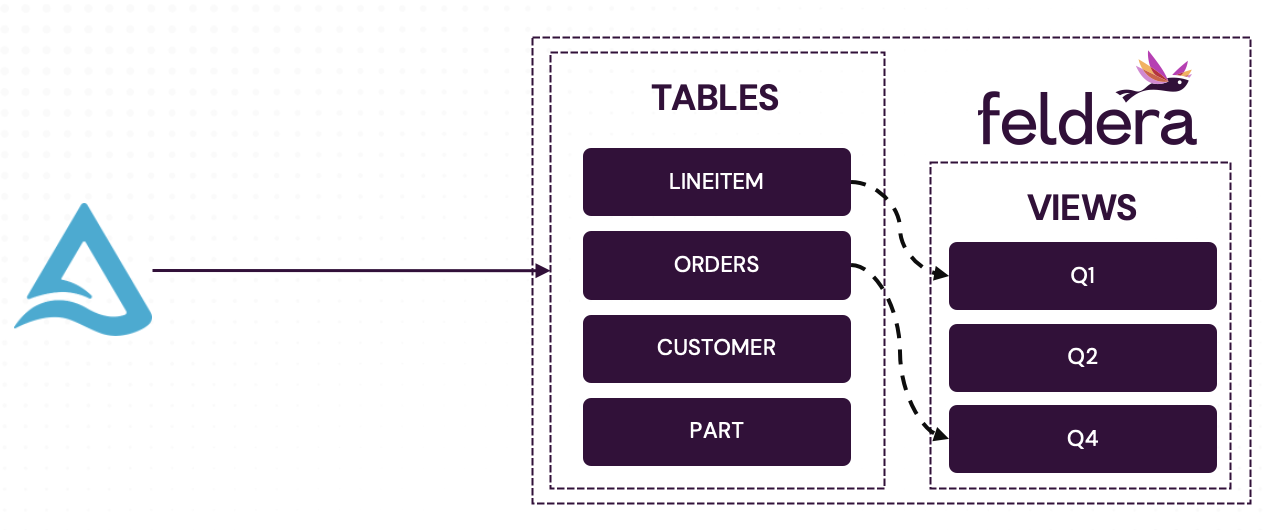
Part 2. Convert the Batch Job into a Feldera Pipeline
We now convert the Spark batch job from the previous section into an always-on, incremental Feldera pipeline. Specifically, in this section of the tutorial we:
- Create Feldera tables and configure them to ingest input records from the Delta Lake.
- Define a set of views identical to the ones we declared in Spark.
- Load initial table snapshots and compute initial contents of the views.
- Demonstrate incremental computation: add new records to the tables and observe instant changes to the views.
The implementation described in this section is available as a pre-packaged example in the Feldera online sandbox as well as in your local Feldera installation.
Full Feldera SQL code
CREATE TABLE LINEITEM (
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
) WITH (
'connectors' = '[{
"transport": {
"name": "delta_table_input",
"config": {
"uri": "s3://batchtofeldera/lineitem",
"aws_skip_signature": "true",
"aws_region": "ap-southeast-2",
"mode": "snapshot_and_follow"
}
}
}]'
);
CREATE TABLE ORDERS (
O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL
) WITH (
'connectors' = '[{
"transport": {
"name": "delta_table_input",
"config": {
"uri": "s3://batchtofeldera/orders",
"aws_skip_signature": "true",
"aws_region": "ap-southeast-2",
"mode": "snapshot_and_follow"
}
}
}]'
);
CREATE TABLE PART (
P_PARTKEY INTEGER NOT NULL,
P_NAME VARCHAR(55) NOT NULL,
P_MFGR CHAR(25) NOT NULL,
P_BRAND CHAR(10) NOT NULL,
P_TYPE VARCHAR(25) NOT NULL,
P_SIZE INTEGER NOT NULL,
P_CONTAINER CHAR(10) NOT NULL,
P_RETAILPRICE DECIMAL(15,2) NOT NULL,
P_COMMENT VARCHAR(23) NOT NULL
) WITH (
'connectors' = '[{
"transport": {
"name": "delta_table_input",
"config": {
"uri": "s3://batchtofeldera/part",
"aws_skip_signature": "true",
"aws_region": "ap-southeast-2",
"mode": "snapshot_and_follow"
}
}
}]'
);
CREATE TABLE CUSTOMER (
C_CUSTKEY INTEGER NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INTEGER NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
) WITH (
'connectors' = '[{
"transport": {
"name": "delta_table_input",
"config": {
"uri": "s3://batchtofeldera/customer",
"aws_skip_signature": "true",
"aws_region": "ap-southeast-2",
"mode": "snapshot_and_follow"
}
}
}]'
);
CREATE TABLE SUPPLIER (
S_SUPPKEY INTEGER NOT NULL,
S_NAME CHAR(25) NOT NULL,
S_ADDRESS VARCHAR(40) NOT NULL,
S_NATIONKEY INTEGER NOT NULL,
S_PHONE CHAR(15) NOT NULL,
S_ACCTBAL DECIMAL(15,2) NOT NULL,
S_COMMENT VARCHAR(101) NOT NULL
) WITH (
'connectors' = '[{
"transport": {
"name": "delta_table_input",
"config": {
"uri": "s3://batchtofeldera/supplier",
"aws_skip_signature": "true",
"aws_region": "ap-southeast-2",
"mode": "snapshot_and_follow"
}
}
}]'
);
CREATE TABLE PARTSUPP (
PS_PARTKEY INTEGER NOT NULL,
PS_SUPPKEY INTEGER NOT NULL,
PS_AVAILQTY INTEGER NOT NULL,
PS_SUPPLYCOST DECIMAL(15,2) NOT NULL,
PS_COMMENT VARCHAR(199) NOT NULL
) WITH (
'connectors' = '[{
"transport": {
"name": "delta_table_input",
"config": {
"uri": "s3://batchtofeldera/partsupp",
"aws_skip_signature": "true",
"aws_region": "ap-southeast-2",
"mode": "snapshot_and_follow"
}
}
}]'
);
CREATE TABLE NATION (
N_NATIONKEY INTEGER NOT NULL,
N_NAME CHAR(25) NOT NULL,
N_REGIONKEY INTEGER NOT NULL,
N_COMMENT VARCHAR(152)
) WITH (
'connectors' = '[{
"transport": {
"name": "delta_table_input",
"config": {
"uri": "s3://batchtofeldera/nation",
"aws_skip_signature": "true",
"aws_region": "ap-southeast-2",
"mode": "snapshot_and_follow"
}
}
}]'
);
CREATE TABLE REGION (
R_REGIONKEY INTEGER NOT NULL,
R_NAME CHAR(25) NOT NULL,
R_COMMENT VARCHAR(152)
) WITH (
'connectors' = '[{
"transport": {
"name": "delta_table_input",
"config": {
"uri": "s3://batchtofeldera/region",
"aws_skip_signature": "true",
"aws_region": "ap-southeast-2",
"mode": "snapshot_and_follow"
}
}
}]'
);
create materialized view q1
as select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
lineitem
where
l_shipdate <= date '1998-12-01' - interval '90' day
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
create materialized view q2
as select
s_acctbal,
s_name,
n_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
from
part,
supplier,
partsupp,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 15
and p_type like '%BRASS'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'EUROPE'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp,
supplier,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'EUROPE'
)
order by
s_acctbal desc,
n_name,
s_name,
p_partkey
limit 100;
create materialized view q3
as select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '1995-03-15'
and l_shipdate > date '1995-03-15'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate
limit 10;
create materialized view q4
as select
o_orderpriority,
count(*) as order_count
from
orders
where
o_orderdate >= date '1993-07-01'
and o_orderdate < date '1993-07-01' + interval '3' month
and exists (
select
*
from
lineitem
where
l_orderkey = o_orderkey
and l_commitdate < l_receiptdate
)
group by
o_orderpriority
order by
o_orderpriority;
create materialized view q5
as select
n_name,
sum(l_extendedprice * (1 - l_discount)) as revenue
from
customer,
orders,
lineitem,
supplier,
nation,
region
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
and l_suppkey = s_suppkey
and c_nationkey = s_nationkey
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'ASIA'
and o_orderdate >= date '1994-01-01'
and o_orderdate < date '1994-01-01' + interval '1' year
group by
n_name
order by
revenue desc;
create materialized view q6
as select
sum(l_extendedprice * l_discount) as revenue
from
lineitem
where
l_shipdate >= date '1994-01-01'
and l_shipdate < date '1994-01-01' + interval '1' year
and l_discount between .06 - 0.01 and .06 + 0.01
and l_quantity < 24;
create materialized view q7
as select
supp_nation,
cust_nation,
l_year,
sum(volume) as revenue
from
(
select
n1.n_name as supp_nation,
n2.n_name as cust_nation,
year(l_shipdate) as l_year,
l_extendedprice * (1 - l_discount) as volume
from
supplier,
lineitem,
orders,
customer,
nation n1,
nation n2
where
s_suppkey = l_suppkey
and o_orderkey = l_orderkey
and c_custkey = o_custkey
and s_nationkey = n1.n_nationkey
and c_nationkey = n2.n_nationkey
and (
(n1.n_name = 'FRANCE' and n2.n_name = 'GERMANY')
or (n1.n_name = 'GERMANY' and n2.n_name = 'FRANCE')
)
and l_shipdate between date '1995-01-01' and date '1996-12-31'
) as shipping
group by
supp_nation,
cust_nation,
l_year
order by
supp_nation,
cust_nation,
l_year;
create materialized view q8
as select
o_year,
sum(case
when nation = 'BRAZIL' then volume
else 0
end) / sum(volume) as mkt_share
from
(
select
year(o_orderdate) as o_year,
l_extendedprice * (1 - l_discount) as volume,
n2.n_name as nation
from
part,
supplier,
lineitem,
orders,
customer,
nation n1,
nation n2,
region
where
p_partkey = l_partkey
and s_suppkey = l_suppkey
and l_orderkey = o_orderkey
and o_custkey = c_custkey
and c_nationkey = n1.n_nationkey
and n1.n_regionkey = r_regionkey
and r_name = 'AMERICA'
and s_nationkey = n2.n_nationkey
and o_orderdate between date '1995-01-01' and date '1996-12-31'
and p_type = 'ECONOMY ANODIZED STEEL'
) as all_nations
group by
o_year
order by
o_year;
create materialized view q9
as select
nation,
o_year,
sum(amount) as sum_profit
from
(
select
n_name as nation,
year(o_orderdate) as o_year,
l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity as amount
from
part,
supplier,
lineitem,
partsupp,
orders,
nation
where
s_suppkey = l_suppkey
and ps_suppkey = l_suppkey
and ps_partkey = l_partkey
and p_partkey = l_partkey
and o_orderkey = l_orderkey
and s_nationkey = n_nationkey
and p_name like '%green%'
) as profit
group by
nation,
o_year
order by
nation,
o_year desc;
create materialized view q10
as select
c_custkey,
c_name,
sum(l_extendedprice * (1 - l_discount)) as revenue,
c_acctbal,
n_name,
c_address,
c_phone,
c_comment
from
customer,
orders,
lineitem,
nation
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate >= date '1993-10-01'
and o_orderdate < date '1993-10-01' + interval '3' month
and l_returnflag = 'R'
and c_nationkey = n_nationkey
group by
c_custkey,
c_name,
c_acctbal,
c_phone,
n_name,
c_address,
c_comment
order by
revenue desc
limit 20;
Table Definitions
We create tables for the TPC-H benchmark, with input connectors configured to read data from our S3 bucket, e.g.:
-- Feldera SQL
CREATE TABLE LINEITEM (
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
) WITH (
'connectors' = '[{
"transport": {
"name": "delta_table_input",
"config": {
"uri": "s3://batchtofeldera/lineitem",
"aws_skip_signature": "true",
"aws_region": "ap-southeast-2",
"mode": "snapshot_and_follow"
}
}
}]'
);
We use the following Delta Lake connector configuration:
uri- location of the Delta table.aws_skip_signature- disables authentication for the public S3 bucket.aws_region- AWS region where the bucket is hosted.mode- Delta Lake ingest mode. Thesnapshot_and_followmode configures the connector to read the current snapshot of the Delta table on pipeline startup, and then switch to thefollowmode, ingesting new updates to the table in real-time.
Refer to Delta Lake Input Connector documentation for details of Delta Lake connector configuration.
Note that our SQL table declaration explicitly lists table columns and their types. In the future Feldera will support extracting these declarations automatically from Delta table metadata.
View definitions
The TPC-H SQL queries we used with Spark can be used in Feldera without modification, e.g.:
create materialized view q1
as select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
lineitem
where
l_shipdate <= date '1998-12-01' - interval '90' day
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
In general, Feldera is not fully compatible with Spark SQL. Existing Spark SQL queries may require porting to Feldera SQL.
Note that we declare the view as materialized, instructing Feldera to maintain the complete up-to-date snapshot of the view, that can be queried using ad-hoc queries as described below.
Backfill
Run the program in the Feldera Sandbox. It should take approximately 5 seconds to process all data in the Delta Lake (867k records). At this point Feldera has ingested all records in the Delta tables, computed the initial contents of the views, and is ready to process incremental input changes.
We can inspect materialized tables and views using ad-hoc queries, e.g., type the following query in the Ad-Hoc Queries tab in the Feldera Web Console:
SELECT * FROM q1;
Output:
| l_returnflag | l_linestatus | sum_qty | sum_base_price | sum_disc_price | sum_charge | avg_qty | avg_price | avg_disc | count_order |
|---|---|---|---|---|---|---|---|---|---|
| A | F | 3774200 | 5320753880.69 | 5054096266.682 | 5256751331.449 | 25.53 | 36002.12 | 0.05 | 147790 |
| N | O | 7459297 | 10512270008.9 | 9986238338.384 | 10385578376.585 | 25.54 | 36000.92 | 0.05 | 292000 |
| R | F | 3785523 | 5337950526.47 | 5071818532.942 | 5274405503.049 | 25.52 | 35994.02 | 0.04 | 148301 |
| N | F | 95257 | 133737795.84 | 127132372.651 | 132286291.229 | 25.3 | 35521.32 | 0.04 | 3765 |
Incremental changes
We have configured the Delta Lake connectors in the snapshot_and_follow mode,
which ingests changes from the transaction log of the Delta table in real-time
following initial backfill. Unfortunately, the tables in our demo are static, so we
will not observe any changes this way. Instead we demonstrate incremental
computation by using ad hoc queries to add a new LINEITEM:
INSERT INTO LINEITEM VALUES (1, 5, 4, 1, 50, 0.80, 0.65, 0.10, 'B', 'C', '1998-09-01', '1998-09-01', '1998-09-01', 'DELIVER IN PERSON', 'TRUCK', 'new record insertion')
This query completes instantly, returning the number of inserted records:
| count |
|---|
| 1 |
At this point Feldera has added the new record to the input table and incementally
updated all views affected by the change. We can for instance view the updated output
of q1:
SELECT * FROM q1;
| l_returnflag | l_linestatus | sum_qty | sum_base_price | sum_disc_price | sum_charge | avg_qty | avg_price | avg_disc | count_order |
|---|---|---|---|---|---|---|---|---|---|
| A | F | 3774200 | 5320753880.69 | 5054096266.682 | 5256751331.449 | 25.53 | 36002.12 | 0.05 | 147790 |
| N | O | 7459297 | 10512270008.9 | 9986238338.384 | 10385578376.585 | 25.54 | 36000.92 | 0.05 | 292000 |
| R | F | 3785523 | 5337950526.47 | 5071818532.942 | 5274405503.049 | 25.52 | 35994.02 | 0.04 | 148301 |
| N | F | 95257 | 133737795.84 | 127132372.651 | 132286291.229 | 25.3 | 35521.32 | 0.04 | 3765 |
| B | C | 50 | 0.80 | 0.28 | 0.308 | 50 | 0.80 | 0.65 | 1 |
Note the new row that has been added to the view.
Recall that with Spark, every input change, no matter how small, required running the entire batch job from scratch.
There is another way to observe incremental changes in Feldera. Select the set of views you are interested in in the Changes Stream tab in the Web Console and insert more records using ad-hoc queries. The corresponding changes will show up in the Change Stream tab.
Takeaways
- We converted the Spark batch job into an always-on, incremental pipeline.
- We demonstrated incremental computation by adding a new record and instantly observing changes in the output the view, without needing to re-run the pipeline.
In the next part of this tutorial, we will demonstrate how to orchestrate different input connectors in order to ingest historical and real-time data from multiple sources.